이번에 읽을 논문은 Deep Compression으로, SqueezeNet에도 자주 등장하는 중요한 녀석이다.
이 논문을 먼저 읽었어야 하는데.. 그 와중에 또 참여하신 Song Han 교수님.. 역시 TinyML 대가 다우시다.
[후기]
CSR 기법, Codebook을 쓴다는 발상이 획기적이다. 특히 Codebook method는 여러 압축에서 쓰일 수 있을 것 같다.
1. Introduction
로컬 기기에서 딥러닝 모델이 돌아간다면 privacy, network bandwith, real time 등의 장점이 있지만 용량이 크면 불가능하다.
또한 용량이 크면 에너지 소비 역시 많이 하게 된다.
따라서 이를 해결하기 위해, deep compression 기법을 제안한다.
이는 정확도는 유지하면서 용량을 줄인다.
크게 보자면, network를 pruning해서 재학습한 뒤, weight quantization으로 같은 weight를 공유하게 만든다.
그리고 이 effective weight들을 codebook으로 만든 뒤 Huffman coding하여 압축한다.
2. Network Pruning
기존 논문에서 network pruning이 압축에 도움된다는 것을 알 수 있었다.
Pruning하면 parameter가 9~13배 가량 줄어든다.
여기서는 pruning한 후, CSR 혹은 CSC 기법으로 2a+n+1 만 써서 저장할 수 있다(a=non zero element, n=# of row or column).
CSR 기법이란?
COO 기법부터 살펴보자. Sparse Matrix를 최대한 줄이는 기법이다. Data, Row, Column으로 쪼개서 저장하므로(좌표값만 저장한다고 생각) non zero element가 a개라면 3a만큼 memory가 필요하다.
CSR 기법은 여기서 Row값을 그냥 저장하는게 아니라 pointer 형식으로 저장하는 것이다. 좌측 행렬을 보면 행1에는 1개, 행2에는 2개,.. 이런식으로 값들이 존재한다. Row pointer에서 보면 0부터 시작해서 행1의 non zero 개수, 행2의 non zero 개수 만큼 추가로 더한다. 데이터 복원시에는 목표하는 행 k를 'Row pointer[k] - Row pointer[k-1]'로 찾아준다. 그러면 그 차이만큼의 값만큼 non zero value가 있다는 것이므로, Data와 Column에서 대응시켜서 복원하면 된다. 굳이 왜 써야할까? 일반적으로 a > n인 경우가 다수이므로 2a+n+1 > 3a인 경우가 많다. 즉 더 압축할 수 있는 것이다. [출처] : https://www.youtube.com/watch?v=zfqVBGpf3L4
여기서는 이거조차 크다고 생각해서 절대적인 위치를 저장하는게 아니라 index difference를 저장했다.
CSR 기법에 더불어서 더 압축하기 위해 index difference에 대해 제한을 걸었다.
Conv layer는 8bit, FC layer는 5bit이다. 만약 그걸 넘긴다면 0을 추가한다.
Ex.
CSC 기법의 예시이다. Column Pointer에서 index difference를 저장했다. 3 bit로 제한되어 있다고 생각해보자. 여기서 index difference = 2, 3, 8이다. 그러면 [0, 2, 3, 8]이 되어야 하나 3bit 제한이므로 8 대신 0, 1을 넣는다. 따라서 [0, 2, 3, 0, 1]이 된다. [출처] : https://velog.io/@woojinn8/LightWeight-Deep-Learning-3.-Deep-Compression-%EB%A6%AC%EB%B7%B0
3. Trained Quantization and Weight Sharing
Weight 공유를 통해 더욱 더 축소시킬 수 있다.
K-means 알고리즘으로 각 weight들을 묶는다(그래서 나중에 back propagation때도 table 참조 과정이 추가된다).
여기서 중요한 점은, 초기 initialization에서 linear한 것이 좋다는 것이다.
그 이유는 weight는 절댓값이 큰 값이 중요하지, 많은 것은 딱히 중요하지 않다.
그러나 절댓값이 큰 값들은 상대적으로 양이 적어, weight 중 임의로 고르는 forgy 방식이나 density-based 방식은 적절하지 않다.
K-means 보충 설명 여기서는 WCSS(within-cluster sum of squares)를 최소화하도록 했다. $$ argmin∑_{i=1}^k∑_{w∈c_i}∣w−c_i∣^22 $$ 기존과 다른 점은, 모든 network가 학습되고 나서 이 방식을 썼다는 점이다(최종 학습 후 clustering).
이 방식으로 만들게 되면 기존의 n connection * b bits를 n*$log_2(k)$와 centroid k*b bits로 압축 가능해진다.
따라서 압축률은 다음과 같다.
$$r=\frac{nb}{nlog_2(k)+kb}$$
4. Huffman Coding
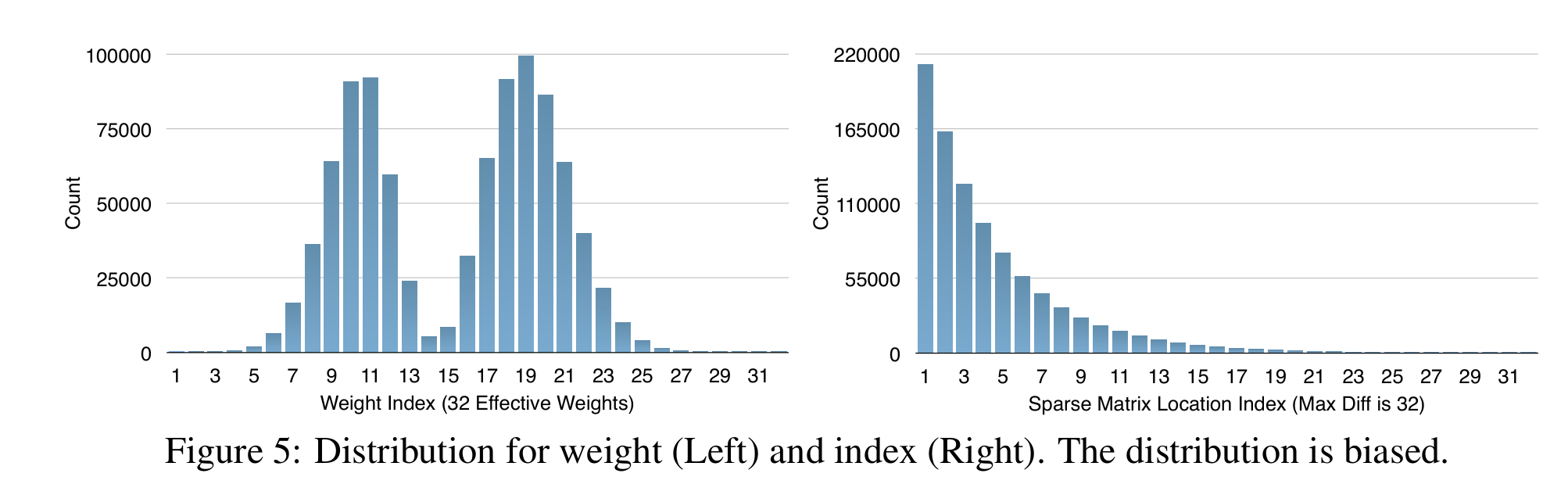
Huffman coding이란 쉽게 말해 자주 등장하는 것을 더 적은 bit로 변환하는 것이다.
특히 분포가 편항될수록 압축에 용이하다.
이 실험은 마침 쌍봉 형태로 quantization되므로 압축 효율이 좋았고, 약 20~30% 가량 축소 가능했다.
5. Experiments
LeNet, AlexNet, VGG-16에 대해 실험했다.
압축률도 높을뿐더러, 일부는 error가 줄어 오히려 accuracy가 높아졌다.
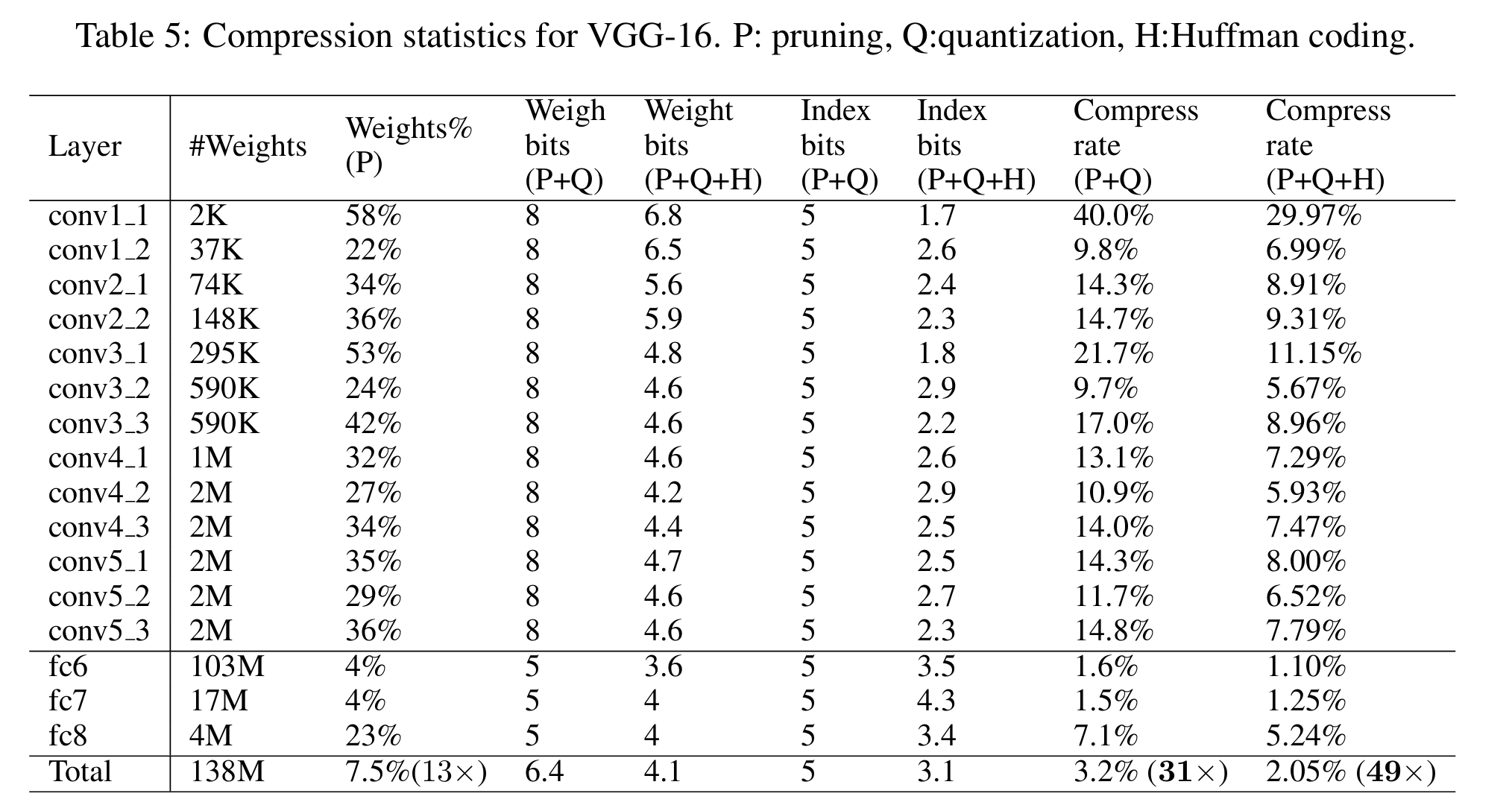
fc layer를 주목하자. ??? : 1.6%가 감소한게 아니라.. 1.6%가 되었다고요?
특히 VGG-16의 FC layer는 초기 크기의 1.6%로 감소시키는 경이로운 현상을 일으켰는데, 이는 곧 불필요한 가중치가 무쟈게 많다는 것이다.
또한 이러한 감소덕에 빠른 처리가 가능해지며, SRAM에서도 적용 가능해졌다.
6. Discussions
6.1 Pruning and Quantization Working Together
Pruning과 Quantization을 같이 쓰면 따로 사용할 때보다 accuracy 손실을 최소화하며 크게 압축할 수 있다.
Figure 7은 bit 수와 정확도의 관계를 보여준다.
보면 알 수 있듯이 pruning 유무는 크게 영향을 안주고, 오히려 pruning하면 좀 더 정확도가 높다.
이는 pruning이 없다면 AlexNet은 6000만 개의 weight를 quantization해야하지만, pruning 후에는 670만 개만 quantization하면 된다.
동일한 centroid가 있다고 가정하면 후자가 더 오류가 적다(clustering 당 개수가 줄어듦).
6.2 Centroid Initialization
앞서 언급했듯이 linear가 큰 centroid 형성할 가능성이 높으므로 성능이 더 좋다.
6.3 Speedup and Energy Efficiency
Deep Compression은 latency-focused이므로 batch size=1로 해서 기다리는 시간을 없도록 했다(실시간 처리는 배치 크기를 1로 해야한다).
FC layer는 model 크기의 대부분(90%)를 차지하고, fast R-CNN의 경우 소모 시간의 약 38%가 FC 였을 정도로 시간 비중도 크다.
그치만 압축이 잘되므로(VGG-16에서 96% 제거) deep compression이 유용하다.
Fig. 9, Fig. 10을 보면 알 수 있듯이 압축한 model이 에너지 소모도 적고 에너지 효율도 좋다.
여기서 주의할 것은 이것들은 모두 batch size = 1이라는 것이다.
왜 자꾸 강조할까? 만약 batch size=1이 아니라면 sparse한 model이 오히려 더 좋지 않을 수 있다.
여기서 보면 batch=64에서 sparse model이 dense model보다 안 좋은 경우가 꽤 있다.
이는 batch size=1이 아닐 때 batching이 memory locality를 개선시키므로 weight가 blocking되고 reuse되므로 그런 것이다.
아래는 ChatGpt 피셜 보충 설명이다. 인덱싱 오버헤드: 희소 행렬은 주로 CSR(압축된 희소 행) 또는 CSC(압축된 희소 열) 형식으로 저장되며, 이 형식에서는 행렬의 실제 값과 더불어 그 위치를 나타내는 인덱스 정보가 필요합니다. 따라서 연산 중 행렬 요소에 접근할 때마다 인덱스를 참조해야 하며, 이는 추가적인 간접 조회 오버헤드를 발생시킵니다.
메모리 접근 패턴의 비연속성: 밀집 행렬에서는 메모리 접근이 연속적으로 이루어지기 때문에 캐시 활용도가 높습니다. 그러나 희소 행렬은 데이터가 흩어져 있어, 캐시를 효율적으로 사용할 수 없고, 메모리 접근의 비연속성 때문에 캐시 미스(cache miss)가 증가합니다.
GPU 및 CPU 라이브러리의 제한: 상용 라이브러리(예: cuSPARSE, MKL SPBLAS)에서는 CSR/CSC 형식의 행렬-벡터 연산에 최적화된 커널을 사용하지만, 밀집 행렬만큼 효율적이지 않을 수 있습니다. 특히 양자화나 가중치 공유 등 간접 조회가 필요한 경우, 현재의 라이브러리에서는 효율적으로 처리되지 않아 추가 시간이 소요될 수 있습니다.
따라서 실시간 탐지(batch size=1)인 경우에 실험한 것임을 유의해야 한다.
Quantization의 경우 8/5 bits로는 정확도 손실이 없었고, 하드웨어 친화적인 8/4 bits에서는 0.01% 손실(무시 가능), 그리고 극단적으로 4/2 bits로 바꾸면 약간의 손실이 생겼다.