이번에 리뷰할 논문은 Fast R-CNN이다. 논문 제목이 곧 모델명.. ㅋㅋㅋ 단순하지만 강렬하다. 기존의 R-CNN이 상당히 느리다는 단점이 있다. GPU로 13초, CPU로 53초.. 실시간은 어림도 없고, 이미지 100장만 분석해도 1300초가 걸린다! 또 기존 모델은 linear SVM, AlexNet(CNN), Bounding Box regressor 3개를 학습시켜야 해서 비효율적이다. 따라서 이러한 단점들을 개선한 것이 이번 Fast R-CNN이다.
한 번 살펴보자!
[후기] 생각보다 술술 읽혀서 좋은 논문이다. 구조도 깔끔하고, 단어 선택도 잘 되어있어 읽기 편했다. 마지막에 저자의 질문을 바탕으로 전개하는 방식이 좋았다. 피니시!
Abstract
기존의 R-CNN보다학습 속도와 테스팅 속도, 그리고 인식 정확도를 개선했다. 그 결과,VGG16을 사용한 Fast R-CNN은 학습은 9배 빠르고, 테스트는 213배 빠르다. SPPnet과 비교해보자면 학습은 약 3배, 테스트는 약 10배가 빠르다. 또한 PASCAL VOC 2012에서 가장 높은 mAP를 달성했다.
1. Introduction
이미지 분류에 비해 객체 인식은 더 어려운 문제이다. 그래서 기존의 방식들은 모델을 여러 단계에 걸쳐 학습했는데 이는 느리고 불편하다.
높은 난이도는2가지 이유때문이다. 1) 객체 위치 후보를 만들어야 한다(이전 논문에서 '제안'이라고 한 것). 2) 이 rough한 위치 후보들로 '정확한' 위치를 찾아야 한다.
이 논문에서는단일 단계 학습 알고리즘을 제안한다. 베이스 모델은VGG16이다(R-CNN은 AlexNet).
그 결과 학습 속도는 R-CNN보다 9배 빠르고 SPPnet보다는 3배 빠르다. 실행 속도는 이미지 당 0.3초(객체 제안 시간 제외)로 최소 10초가 넘어간 R-CNN에 비해 상당한 개선이다. mAP도 PASCAL VOC 2012 기준 66%를 달성했다(R-CNN은 62%).
1.1 R-CNN and SPPnet
R-CNN에는 세 가지 단점이 있다. 1)학습이 multi-stage이다. ConvNet, SVM, Bounding-box regressor 3개나 훈련시켜야 한다 2)학습이 시간, 공간적으로 비효율적이다. 학습을 위한 feature는 추출되어 disk에 써지는데 수백 GB가 필요하고(공간), 이 과정들은 VGG16 기준 GPU로 2.5일 걸렸다(시간). 3)객체 감지가 느리다. VGG16 기준 GPU에서 이미지 당 47초나 걸렸다.
이를 보완하기 위해SPPnet(Spatial pyramid pooling network)이 제안되었다. 이 모델은 계산을 공유함으로써 속도를 올렸다. 기존의 R-CNN이 후보 영역 얻기 -> CNN 학습 -> SVM의 단계를 거쳤다면, SPPnet은 전체 이미지에서 feature를 얻고 이를 사용한다. 그 결과 약 학습은 3배, 테스트는 10~100배 빨라졌다.
다만 SPPnet도 여전히 단점이 있다. 1)여전히 multi-stage를 학습한다. 2)Feature는 아직도 disk에 다 써야 한다. 3)Fine-tuning에서 CNN을 업데이트하지 않는데, 이는 오히려 성능에 제한을 준다.
1.2 Contributions
R-CNN과 SPPnet의 단점을 보완해 Fast R-CNN을 만들었다. Fast R-CNN의 장점은 다음과 같다. 1) 높은 정확도(mAP) 2) 학습이 단일 단계이며, multi-task loss를 사용함 3) 학습이 모든 네트워크 layer를 업데이트함 4) Feature caching에 disk 공간이 필요없음
2. Fast R-CNN architecture and training
Fig. 1은 Fast R-CNN 구조를 보여준다. 전체 이미지를 input으로 받고 객체 위치를 제안한다. 네트워크는 먼저 conv를 통과시키고, max pooling을 해서 conv feature map을 생성한다. 그리고 각 객체 제안마다RoI Pooling layer를 통해 고정된 길이의 feature vector를 추출한다. 각 feature vector는 FC layer로 들어가서 두 개의 output을 만든다. 1) K개의 객체 클래스 + 배경(총 K+1개)까지 해서 나올softmax 확률 2) K개의 객체에 대한 4가지 숫자, 각 숫자는bounding-box 위치를 의미함
2.1 The RoI pooling layer
RoI pooling layer는max pooling을 사용해 관심있는 영역을 작은 feature map으로 바꾼다. 이 영역은 고정된 크기인H*W를 가지며, H와 W는 layer hyperparameter이다. 각 RoI는 (r, c, h, w)로 정의되며, (r, c)는 좌상단 좌표값, (h, w)는 높이와 너비이다.
RoI max pooling은h*w(내가 관심있는 영역 너비, 높이)를H*W(줄여야 하는 크기)로 만드는 것이다. 따라서 윈도우 사이즈는 대략h/H * w/W가 된다. 아래 이미지를 보면 이해가 쉽다.
RoI는 SPPnet의 spatial pyramid pooling layer의 특수 케이스로 볼 수 있다(오직 한 단계뿐인).
참고로 RoI에서 저렇게 어림짐작하여 발생하는 손실을 보완하기 위해 Mask R-CNN에서 RoI Align이 제안되었다.
2.2 Initializing from pre-trained networks
여기서는 3개의 사전학습된 ImageNet을 사용했다. 각각은 5개의 max pooling layer + 5~13개의 conv layer를 가지고 있다. Fast R-CNN에 사용할 때, 사전학습된 네트워크는 세 가지의 변형을 거친다.
1) 마지막 max pooling layer는 RoI pooling layer로 교체된다. 크기는 네트워크의 첫 FC layer에 맞는 H, W로 구성된다(VGG16에서는 H=W=7). 2) 마지막 FC layer와 softmax는 앞서 말한 K+1 개의 softmax 확률과 bounding-box를 만드는 layer로 대체된다.
대체된 layer는 다음을 만든다(section 2 참고). 1) K개의 객체 클래스 + 배경(총 K+1개)까지 해서 나올 softmax 확률 2) K개의 객체에 대한 4가지 숫자, 각 숫자는 bounding-box 위치를 의미함
3) 네트워크는 이미지와 RoI를 input으로 받는다.
2.3 Fine-tuning for detection
SPPnet과 R-CNN의 역전파는 매우 비효율적이다. 왜냐하면 RoI를 다른 이미지에서 뽑았기 때문이다. RoI는 때때로 무진장 커서 전체 이미지를 쓰기도 했기에, 엄청나게 느렸다. 128개의 RoI를 얻으려면 128장의 이미지를 쓴 것이다.
그러나 Fast R-CNN에서는 효율적인 학습을 위해feature 공유를 했다. N개의 이미지를 샘플링하고, 각 이미지에서R/N개의 RoI를 샘플링했다. 만약 N=2, R=128이라면, 총 128개의 RoI를 위해 이미지는 2장만 필요하다! 이는 128장을 쓴 기존의 방식에 비해 거의 64배 빠르다.
한 이미지에서 뽑으면 연관되어 별로 좋지 않을까? 해보니 그렇지 않았다. 오히려 한 단계만에 softmax 분류기와 bb regressor를 학습할 수 있다. -> 효율적! (RoI, SPPnet은 3단계에 걸쳐 학습)
Multi-task loss.
Fast R-CNN의 2가지 output은 다음과 같다(RoI 당). 1) 클래스 확률(총 K+1개)p=(p0,...,pK) 2) Bounding-boxtk=(txk,tyk,twk,thk)
각 RoI는 ground-truth classu와 ground-truth bb regression targetv를 기반으로 학습된다. 식은 다음과 같다.
어후 너무 복잡하다. 하나씩 살펴보자.
이는 실제 클래스 u에 대한 로그 손실이다.
여기서[u≥1]는 아이버슨 괄호로, 참이면 1, 아니면 0을 반환한다. u는 배경일 때 0이고 그 외에는 1보다 크다(=배경이 아니면 항상 1을 반환).
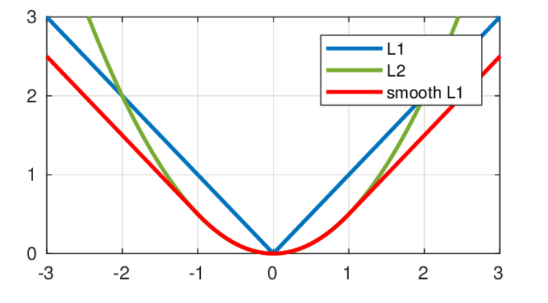
이는 bounding box에 대한 손실이다. Smooth L1은 이상치에 대해 L2보다 덜 민감하다.
λ는 이 두 가지 손실을 조절해주는 역할로, 실험에서는 모두 1을 사용했다. 참고로 여기서vi(ground-truth bounding box target)는 zero mean, unit variance를 가지도록 조정했다(아마도 실제값을 transform 시켜서 저렇게 만든듯).
Mini-batch sampling.
Fine-tuning 과정에서, 각 mini batch는 무작위로 고른 N=2개의 이미지로 구성된다. R=128로, 한 이미지 당 64개의 RoI를 샘플링했다. RoI 중, ground-truth와의 IoU가 0.5가 넘는 약 25%의 RoI만 물체로 선정했다(u≥1). [0.1, 0.5)의 IoU는 배경으로 처리했다(u=0).
데이터 증강은 좌우 대칭(50% 확률) 외에는 하지 않았다.
Back-propagation through RoI pooling layers.
하는 이유: 아니 매번 영역 크기가 다른데 어떻게 back propagation 해요 ㅋㅋ -> 합니다.이미지 출처
보면x23하나가 여러개의 y에 영향을 줄 수 있다.
먼저 forward부터 보자(yrj계산). 간단함을 위해, N=1(이미지 수)이라 가정하겠다(N>1도 자명하다). xi∈R: RoI pooling layer의 i번째 activation input yrj: r번째 RoI로부터 온 layer의 j번째 output
RoI는yrj=xi∗(r,j)를 계산한다. 여기서i∗(r,j)=argmaxi′∈R(r,j)xi′을 의미한다. R(r, j)는 output이yrj인 subwindow 내의 index set이다.
즉 R(r, j) =yrj를 만드는 구역 내 index 집합, 이 구역 내에서 x를 최대로 만드는 index i*(r,j)를 구하고, 이 x 값을yrj로 함
이제, back propagation 식을 보자.
앞서 본 아이버슨 괄호가 또 있다.
이 괄호는 이 index가 x를 최대로 만드는 index일 때 1을 반환한다. 즉 r, j의 구역을 움직인다. 이 와중에 만일yrj를 최대로 만드는 index가 있다면,xi의 기울기에 계속누적시키는 것이다.
SGD hyper-parameters
Softmax 분류기, BB regression 학습에 사용한 초깃값은 다음과 같다.
Zero-mean 가우시안 분포(표준 편차 0.01 / 0.001), Bias = 0
Learning rate : 0.001
Per-layer learning rate = 가중치에는 1, biases에는 2
모멘텀 = 0.9 / Parameter decay = 0.0005
2.4 Scale invariance
1) Brute force 학습 미리 지정된 pixel 크기로 변환 후 학습한다.
2) 이미지 피라미드 학습(multi-scale) 이미지 피라미드로 scale invariance 만든다(고정된 이미지 크기가 아니라 다양하게).
Multi-scale 학습에서, 랜덤하게 피라미드 scale을 샘플링한다(데이터 증강). 단 GPU 메모리 한계로 작은 네트워크에서만 학습했다.
테스트에는 각 이미지의 scale-normalize를 위해 사용한다.
3. Fast R-CNN detection
네트워크의 input = 이미지나 이미지 피라미드 + R개의 객체 제안 테스트에서 R은 대략적으로 2000개 정도이며 이후 45000개까지 확장해서 논의할 것이다. 이미지 피라미드에서, 각 RoI의 scale은 scale된 후 크기가2242pixel에 가깝게 되도록 설정된다.
테스트 RoI r에서 forward pass는 클래스 사후 확률 p와 bb offset r을 출력한다. 이에 대해 detection confidence를 클래스 k에 대해 계산한다. 수식은Pr(class=k∣r)≜pk이다. (수식 살펴보기, 삼각형 등호는 정의한다라는 의미이다, 즉 bb regression r이 주어졌을 때 클래스가 k일 확률을pk로 정의하자 이다) 그리고non-maximum suppression(NMS)을 각 클래스에 독립적으로 시행한다. (NMS는 이전 R-CNN에서도 나왔다, 이는 불필요한 bounding box를 IoU 기반으로 합치는 것이다)
3.1 Truncated SVD for faster detection
이미지 분류에서는 FC보다 conv에서 더 많은 시간을 소비한다. 반면 객체 감지에서는 RoI 계산이 많아서 FC에서 거의 절반 이상의 forward pass 시간을 쓴다. 이러한 시간을 줄이는 방법 = FC layer 계산은truncated SVD를 통해 압축하면 된다!
선형대수 등장..! truncated SVD란?
SVD(Singular Value Decomposition), 특잇값 분해 임의의 직사각 행렬 W에 대해 직교행렬 U, V / 직사각 대각행렬Σ로 분해할 수 있다.
대각행렬에서 0이 아닌 요소를 모두 사용하는 경우는 Full SVD, 0이 아닌 부분을 잘라내어 사용하는 경우(대응되는 U, V도 자른다)Truncated SVD라 부른다.
이 과정을 거치면 parameter는 uv -> t(u+v)로 줄어든다. 만일 t가 min(u, v)보다 확연히 작다면 효과가 뛰어날 것이다. (풀이 및 의문 : uxt + vxt + txt 에서 대각행렬은 txt개가 아니라 t개, 따라서 t(u+v)라는데.. t(u+v+1)이 아닌지? 이정도는 무시하는건가)
따라서 가중치가 W인 기존의 FC layer를 가중치가ΣtVT(bias=0)인 FC layer 하나 + 가중치가 U(bias = W bias)인 FC layer 하나 로 결합해서 대체했다(non linearity 없이!).
4. Main results
사실상 이번 섹션의 요약이다. 세 가지 발전이 있다. 1) VOC07, 2010, 2012에 대해 SOTA mAP 2) R-CNN, SPPnet보다 빠른 학습과 테스트 3) VGG16에서 fine-tuning해서 더 나은 mAP 얻음
4.1 Experimental setup
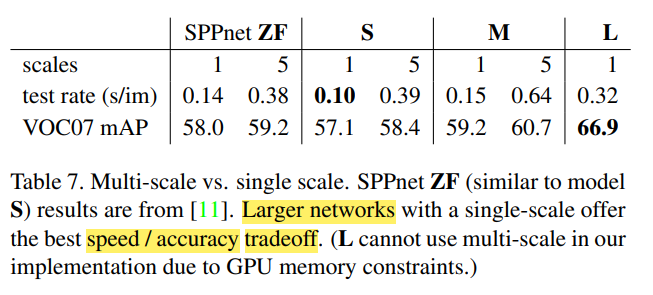
[용어 설명] S : AlexNet(R-CNN에 쓴 것) 기반 M : VGG_CNN_M_1024 기반(S와 깊이는 같지만 더 넓음) L : VGG16 기반 모든 실험은 single-scale 학습 및 테스트이다(s=600).
4.2 VOC 2010 and 2012 results
VOC12에서 Fast R-CNN은 최고의 결과를 냈다. 65.7%의 mAP를 달성했다(추가 데이터와 함께할 땐 68.4%). 또 R-CNN 기반인 다른 방법들보다 속도도 빨랐다.
VOC10에서는 SegDeepM에 밀렸다(67.2% vs 66.1%). SegDeepM은 Markov 랜덤 필드 + R-CNN 기반 모델이며 VOC12에 segmentation 주석까지 추가해 학습했기 때문이다. 만일 SegDeepM에 R-CNN 대신 Fast R-CNN이 있었다면 더 좋은 성적을 냈을 것이다.
07++12 학습 세트를 쓴 경우 Fast R-CNN은 68.8%의 mAP로 SegDeepM보다 더 낫다. (근데 SegDeepM도 똑같이 학습해보면... 음...)
4.3 VOC 2007 results
VGG16 기반으로 Fast R-CNN과 R-CNN/SPPnet을 비교해보자. 각 방법들은 bb regression도 사용했다.
VGG16 SPPnet은 5 scale을 사용했음에도 Fast R-CNN(single scale)보다 좋지 않았다. mAP 차이는 두드러진다(63.1% vs 66.9%). R-CNN은 mAP 66.0%를 도달했다.
여담으로, SPPnet은 PASCAL에서 'difficult'로 마킹된 예제를 제외하고 학습했다. 만일 Fast R-CNN도 그렇게 한다면 mAP는 68.1%까지 상승한다. 다른 실험들은 모두 'difficult' 예제를 사용했다.
4.4 Training and testing time
학습/테스팅 속도가 비약적으로 상승했다. 특히 truncated SVD 사용시 더 압도적이다. 그럼에도 mAP는 훨씬 좋다(truncated SVD 사용시 mAP 약간 감소).
Fast R-CNN은 또한 수백 기가의 저장 공간을 절약했다(feature 임시 저장 안함).
Truncated SVD
Truncated SVD를 사용하면 mAP의 약간의 감소(0.3정도)로 비약적 속도 상승을 이뤄낼 수 있다. 또 추가적인 fine-tuning도 필요없다.
Fig. 2를 보면 알 수 있듯이, FC layer가 기존에는 총 시간의 약 45%나 차지했다. 그러나 truncated SVD를 사용해 약간의 mAP 손실은 있지만 속도가 엄청나게 향상되었다. (총 시간 320ms -> 223ms, 약 30% 감소/mAP 0.3 감소)
4.5 Which layers to fine-tune?
SPPnet은 FC layer들만 fine-tuning했다. 그렇지만 저자들은 깊은 네트워크는 conv layer도 fine-tuning해야 한다고 가설을 세웠다. 따라서 이를 위해 일부 layer를 freeze하고 실험했다. 비교 대상은 SPPnet L(VGG16 기반)으로, FC layer만 fine-tuning된 모델이다.
과연 정말모든 conv layer가 fine-tune되어야할까? 아니다! Conv1(가장 먼저 나오는 conv layer)는 일반적인 특성을 수집하기에 굳이 fine-tuning할 필요가 없다(mAP 상승에 큰 영향 x).
VGG16에서,conv3_1부터 위 /conv2_1부터 위 / FC부터 위 세 가지로 나누어서 실험했다. (conv1_1은 GPU 부족)
Conv2_1부터 위로 학습은conv3_1부터와 비교해서 학습 속도가 1.3배나 느려지지만(9.5시간->12.5시간), mAP는 0.3만 좋아졌다. 반면conv3_1부터 위로 학습은 FC만 fine-tuning할때보다 mAP가 5.5 높다. (성능conv2_1부터 >conv3_1부터 >> FC만)
따라서 이 논문에서 나오는 모든 Fast R-CNN(VGG16 기반)은conv3_1부터 fine-tuning했다. (굳이 0.3 더 높이자고 학습 속도 손해 x) S, M(VGG16말고 다른 것 기반) 모델은 conv2부터 fine-tune했다.
5. Design evaluation
PASCAL VOC07 데이터셋으로 세 가지 실험을 해보자. 이를 통해 디자인을 평가할 것이다.
5.1 Does multi-task trianing help?
Multi-task 학습은 간편하지만, 객체 탐지 성능 향상에도 도움을 줄까? (Multi task : BB regression + 클래스 분류 동시에)
이를 위해 여러개로 나누어서 테스트했다. 1) Baseline,λ=0, BB regressor 없음 2) Multi-task 학습(λ=1, 학습에는 BB 있음), 그러나 테스트에는 BB regressor 없음 3) Stage-wise 학습(클래스 먼저 학습하고 BB 학습), 테스트에도 BB regressor 있음 4) Multi-task 학습 + 테스트 BB regressor
1) -> 2)로 갈 때 약 0.8~1.1의 mAP 상승이 있었다(Multi-task의 이점). 또 stage-wise가 multi-task보다 낮은 성능임을 알 수 있었다(역시 Multi-task의 이점).
즉,multi-task 학습은 stage-wise/아예 BB 안쓰고 학습 보다더 좋은 성능을 낸다.
5.2 Scale invariance: to brute force or finesse?
Brute force 방식(single scale) / 이미지 피라미드 방식(multi-scale) 비교한다. s : 이미지의 가장 짧은 부분의 길이
먼저 모든 single-scale 실험은 s=600 고정한다. 단 가장 긴 쪽이 1000을 넘지 않게 하며 이미지 비율을 고정했기에, s가 600보다 작을 수 있다. PASCAL 이미지가 384x473 크기여서 여기서는 1.6배 커진다.
Multi-scale에서는 s를 {480, 576, 688, 864, 1200}으로 지정했다. 그러나 가장 긴 쪽의 길이가 2000을 넘지 않도록 했다.
Table 7은 그 결과를 보여준다. 놀라운 점은 single scale과 multi scale이 그리 큰 차이가 나지 않는다는 것이다. 또 속도/정확도의 tradeoff가 생기는데, multi-scale은 속도는 무척 느려지는 반면 mAP 약간 증가한다.
Single-scale이 속도와 정확도의 tradeoff를 잘 보여주는 관계로(확확 늘어남), 이 장의 남은 실험은 single-scale(s=600)으로 할 예정이다.
5.3 Do we need more training data?
학습 데이터가 많다면 성능이 좋아질까? 타 논문에 따르면 mAP는 수백~수천 학습 예제에서 포화되었다(성능 발전이 없다)고 했다.
그러나 데이터셋을 늘리니(VOC07+VOC12) mAP가 66.9%에서 70.0%까지 상승했다. 즉 학습 데이터의 증가로 성능 발전을 이뤄냈다. (다만 포화되는지는 모름)
5.4 Do SVMs outperform softmax?
과연 softmax(Fast R-CNN)가 SVM(R-CNN/SPPnet)보다 성능이 좋을까? 이를 위해 Fast R-CNN에서 SVM을 사용해 실험했다.
결과는 softmax가 SVM보다 약간 낫다(0.1, 0.8 mAP). 따라서softmax만으로도 충분하다. (one-vs-rest인 SVM과 달리 sofmtax는 클래스 간 경쟁을 시킨다)
5.5 Are more proposals always better?
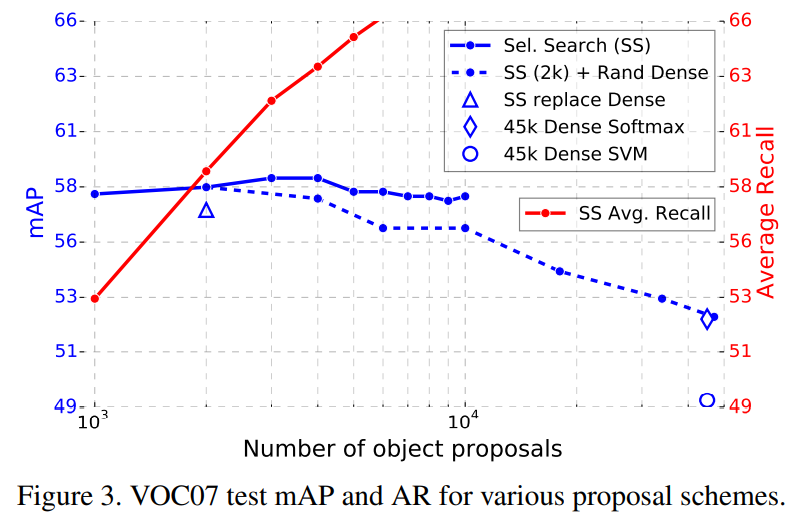
영역 제안 수가 증가하면 성능이 더 좋아질까?
꼭 그런건 아니다. 처음에 약간 증가하지만 오히려 너무 많아지면 감소한다. 따라서 영역 제안이 늘어난다고 성능이 좋아지지는 않는다. (오히려 sparse한 영역 제안이 dense한 영역 제안보다 성능이 좋다)
6. Conclusion
이 논문에서는 더 빠르고 성능도 좋은 Fast R-CNN을 제안했다. SOTA 결과를 내면서, 동시에 다양한 실험도 할 수 있엇다. 그 중 하나로 sparse한 영역 제안이 성능 향상을 준다는 것이다. (이는 과거에는 비용 문제로 실험하지 못했다) 이 외에도 발견되지 못한 다양한 테크닉이 있을 것이고, 이는 아마 객체 탐지 발전에 큰 도움을 줄 것이다.