Neural Network를 빠르고 가볍게 만드는 방법 중 하나는 Pruning(가지치기)이다.
Pruning이란 쉽게 말해서 node들을 가지치기하듯 잘라내서 가볍게 만들면서, 정확도 감소는 적게 만드는 기법이다.
본 강의에서는 그러한 기법들의 장,단점과 사용법에 대해서 알려준다.

Pruning 분류
먼저 Pruning을 크게 분류해보자면 아래와 같이 분류할 수 있다.
좌측으로 갈수록 불규칙하고, 우측으로 갈수록 규칙적이다.
불규칙의 장점은 압축율이 높다는 점, 그리고 redundant weight들을 찾기가 쉽다는 점이다.
단점이라면 저렇게 무작위로 되어있으므로 weight 크기 자체를 압축하기가 어렵다.
규칙의 장점은 즉각적으로 속도를 높일 수 있다는 점이다.
단순히 pruning해서도 그렇지만, 불필요한 weight들을 모두 잘라내므로 '연산' 자체를 줄일 수 있다.
단점이라면 압축률이 낮다는 점이다.
추후 설명하겠지만, 모든 channel을 일정하게 pruning하는 것 보다는 channel마다 다르게 하는게 더 성능이 낫다.
1. Pruning Criterion
어떤 element, channel을 pruning해야 할까?
1.1 Magnitude-based Pruning
Element wise라면, 단순히 weight의 크기를 기준으로 할 수 있다.
만약 row wise라면, L1 혹은 L2 norm(Lp norm도 가능) 기준으로 고를 수 있다.
1.2 Scaling-based Pruning
혹은, channel의 scaling factor가 작은 것들을 pruning 할 수 있다.
아무래도 scaling factor는 그 channel의 output과 곱해지는 값이라서 작다면 그냥 없애도 된다는 것이다.
1.3 Second-Order-based Pruning
혹은 pruning 한 output의 reconstruction error를 최소화하도록 pruning 할 수도 있다.
이처럼 기준은 다양하다. 핵심은 최대한 '쓸모없는' 것을 잘라내는 가지치기의 원리를 적용했다는 점이다.
2. Pruning ratio
Pruning할 비율은 어떻게 정해야 할까?
먼저 uniform shrink보다는 channel별로 다르게 pruning하는 것이 더 성능이 좋다는 것을 알아야 한다.
2.1 Sensitivity 기반
이때 도입하는 개념이 sensitivity이다.
쉽게 말해 어떤 layer는 pruning에 민감하고, 어떤 layer는 줄이든 말든 무관하게 반응한다는 것이다.
측정 방법은 간단하다.
Layer Li에 대해 각각 r=0.1,0.2,...,0.9를 골라 pruning한다.
그리고 그때의 accuracy를 비교해본다. 그러면 아래와 같이 나올 것이다.
여기서 L1은 줄이든 말든 크게 accuracy가 변하지 않고, L0는 매우 민감하게 변하는 것을 볼 수 있다.
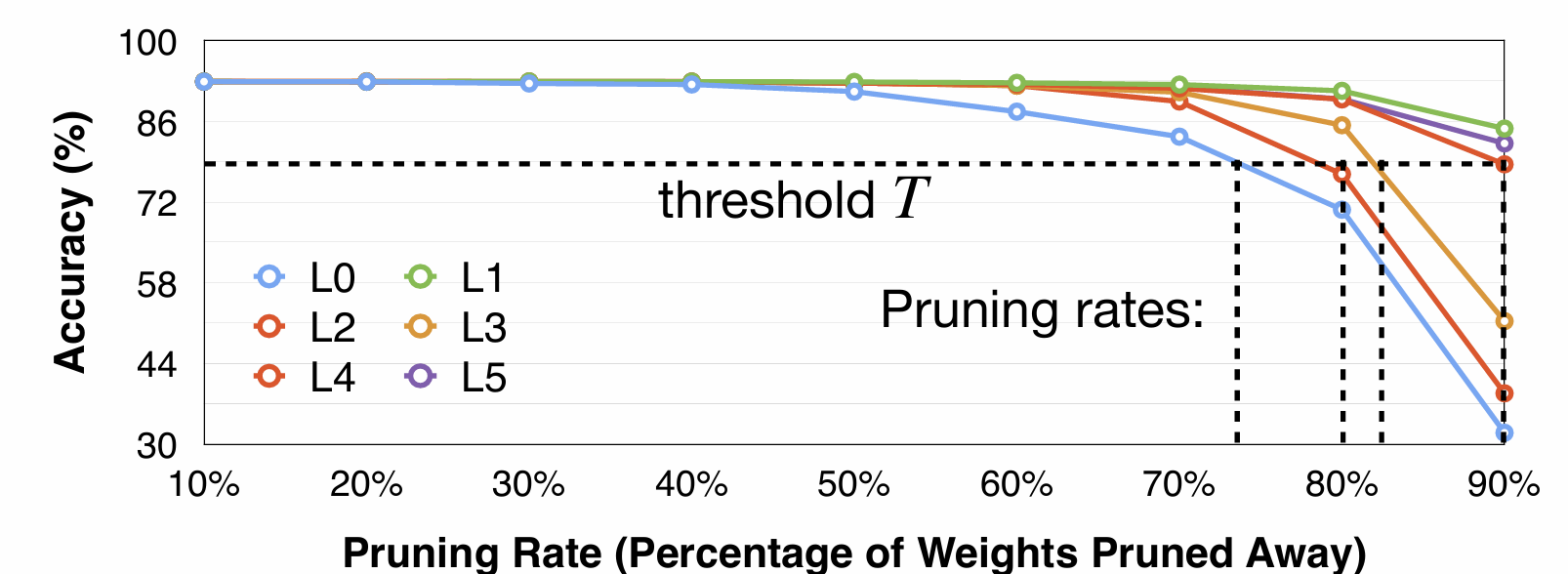
그러면 우리는 정확도 변화의 threshold T를 정해 pruning rate를 최대로 정할 수 있다.
이 방법의 단점은 layer 간 상호작용을 고려하지 않았다는 점이다.
2.2 Pruning by reinforcement learning
따라서 이에 대한 해결책으로 제시된 것이 사람에 의한 노가다(..)가 아니라 reinforcement learning이다.
이를 AMC(AutoML for Model Compression)이라고 한다.
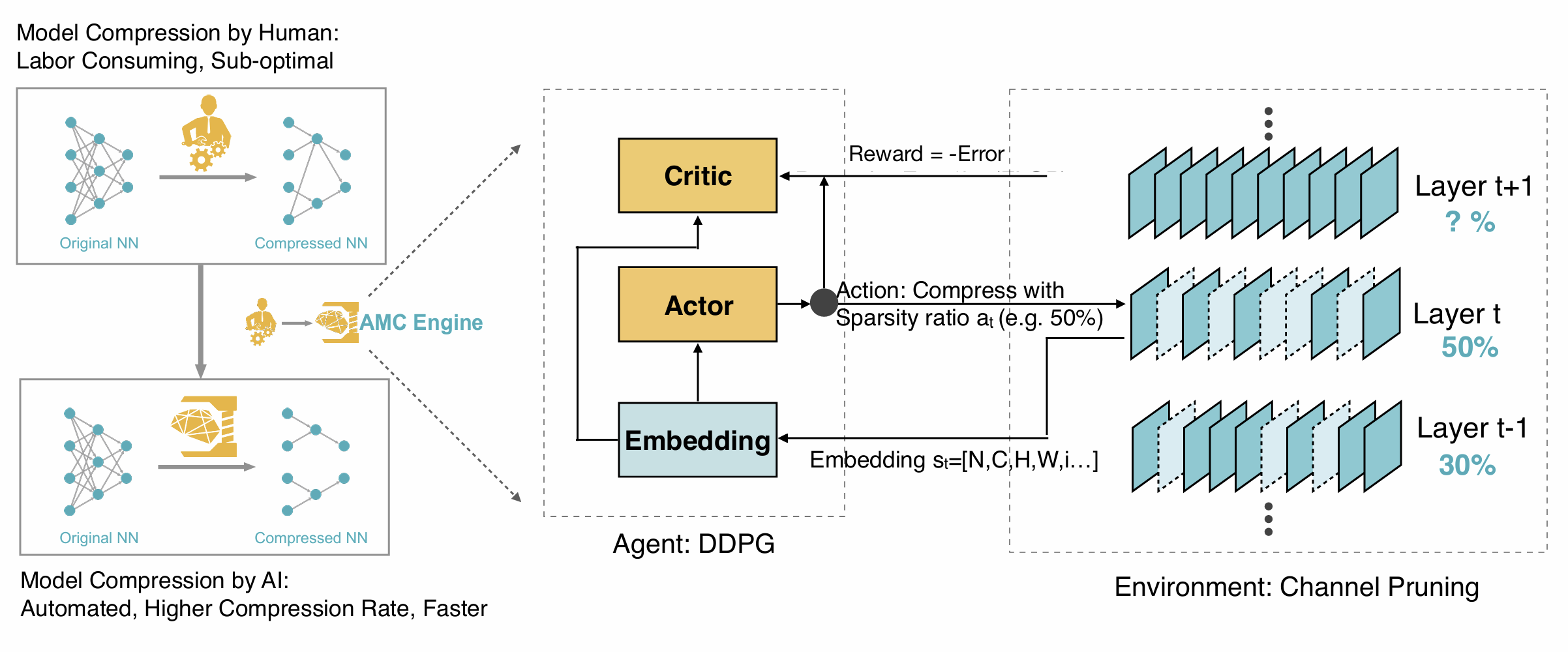
이처럼 reward를 설정하고 기계 노가다(..)를 돌린다는 것이다.
놀랍게도 인간 전문가보다 더 나은 결과를 얻어냈다고 한다.
2.3 NetAdapt
혹은 rule-based로 적용할 수도 있다.
이는 NetAdapt라는 논문을 기반으로 하는 기법이다.
특이한 점은 latency를 기준으로 pruning을 한다.
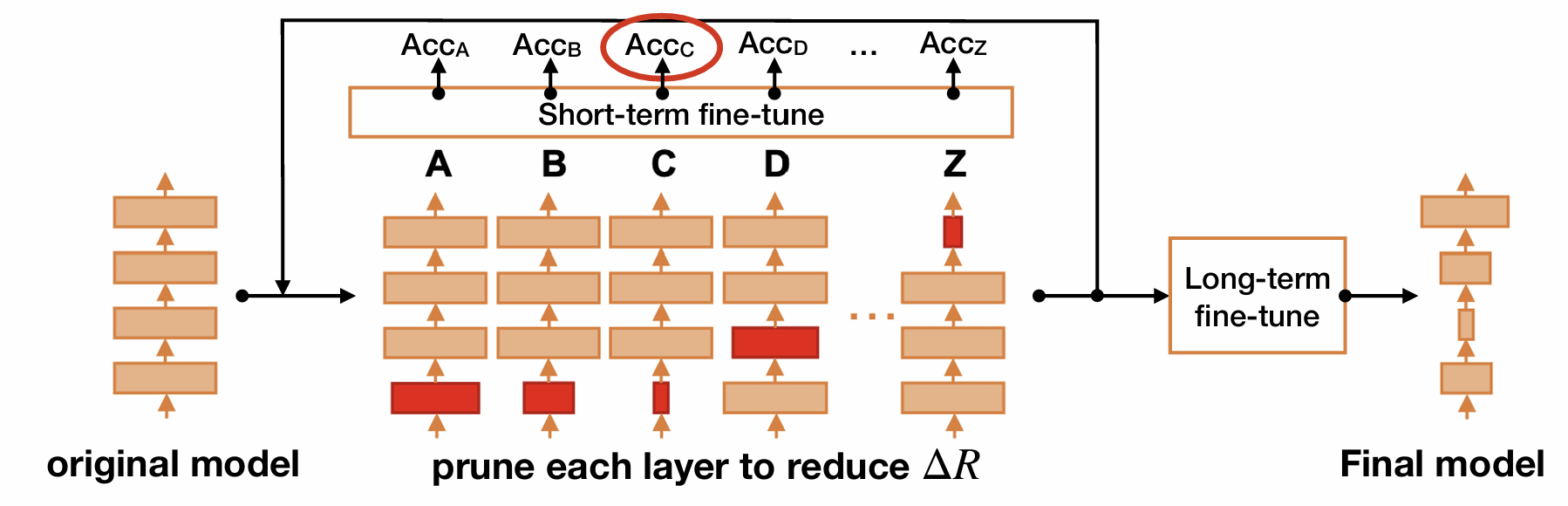
각 layer를 pruning했을 때 latency를 ΔR만큼 줄이도록 목표한 다음, short-term fine-tune(10K정도)를 진행한다.
이때 highest accuracy를 가진 pruning layer를 골라 반복한다.
그리고 마지막으로 최종 정확도를 높이기 위해 Long-term fine-tune을 한다.
결국 또 노가다인 것이다.
3. Fine-tune/Training
자 이렇게 얻어낸 pruning을 fine-tuning하면 더 좋아질 것이다. 어떻게 할까?
일반적으로 pruning -> fine-tuning을 거친다.
근데 그것보다 더 좋은 것은, 순차적 pruning을 하며 fine-tuning하는 것이다.
30% pruning -> fine-tuning -> 50% pruning -> fine-tuning -> 70% pruning -> fine-tuning ...
이런 식으로 한다.
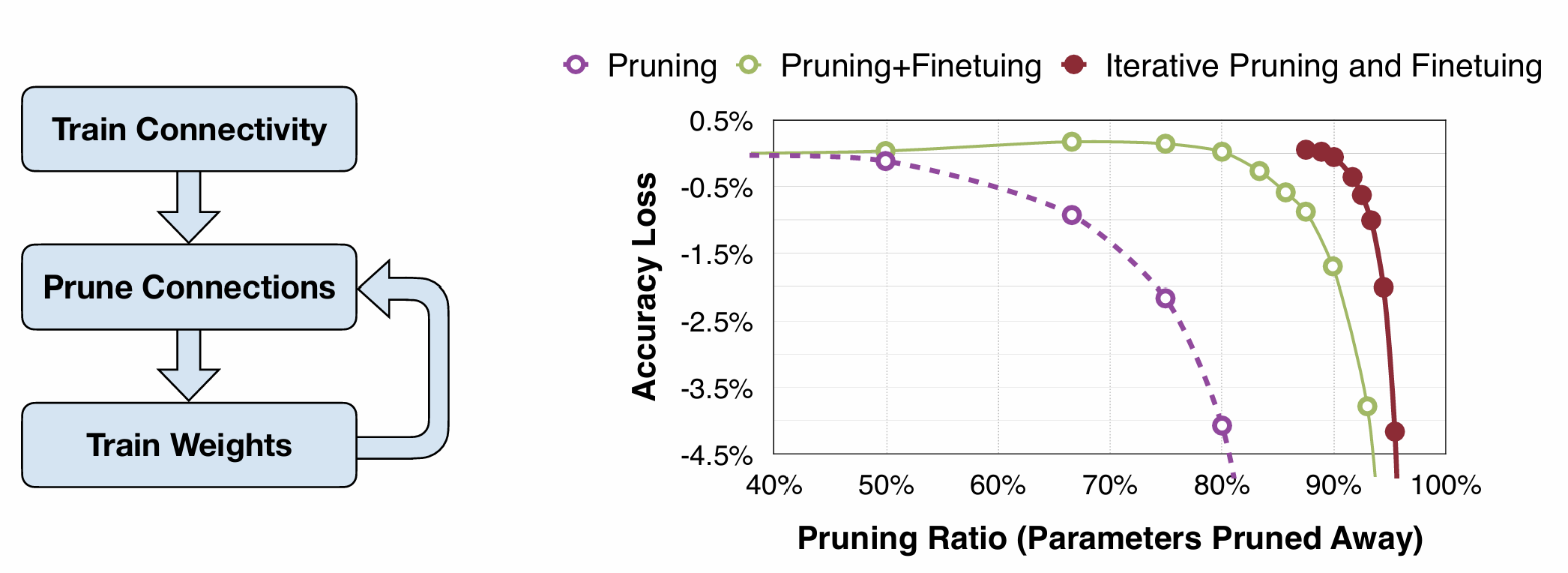
Pruning만 했을 때, 그리고 pruning-finetuning 1회만 했을 때보다 성능이 훨씬 낫다.
이외에도 regularization 등을 하는 기법이 있다.